Dask Read Parquet
Dask Read Parquet - Web read a parquet file into a dask dataframe. This reads a directory of parquet data into a dask.dataframe, one file per partition. Web when compared to formats like csv, parquet brings the following advantages: Web read a parquet file into a dask dataframe. 2 the text of the error suggests that the service was temporarily down. Read_hdf (pattern, key[, start, stop,.]) read hdf files into a dask dataframe. Web dask is a great technology for converting csv files to the parquet format. Raw_data_df = dd.read_parquet (path='dataset/parquet/2015.parquet/') i. Pandas is good for converting a single csv. Web parquet is a popular, columnar file format designed for efficient data storage and retrieval.
Web read a parquet file into a dask dataframe. First, dask is not splitting your input file, thus it reads all the data in a single partition,. Web create_metadata_filepyarrowcompute_kwargsconstruct a global _metadata file from a list of parquet files. In layman language a parquet is a open source file format that is designed. Web 3 answers sorted by: Web when compared to formats like csv, parquet brings the following advantages: This reads a directory of parquet data into a dask.dataframe, one file per partition. Web dask is a great technology for converting csv files to the parquet format. Web below you can see an output of the script that shows memory usage. Web read a parquet file into a dask dataframe.
Web i attempted to do that using dask.delayed (which would allow me to decide which file goes into which. Web when compared to formats like csv, parquet brings the following advantages: Web trying to read back: Raw_data_df = dd.read_parquet (path='dataset/parquet/2015.parquet/') i. Web i see two problems here. Web create_metadata_filepyarrowcompute_kwargsconstruct a global _metadata file from a list of parquet files. 4 this does work in fastparquet on master, if using either absolute paths or explicit relative paths:. Web read a parquet file into a dask dataframe. Read_hdf (pattern, key[, start, stop,.]) read hdf files into a dask dataframe. Web 1 answer sorted by:
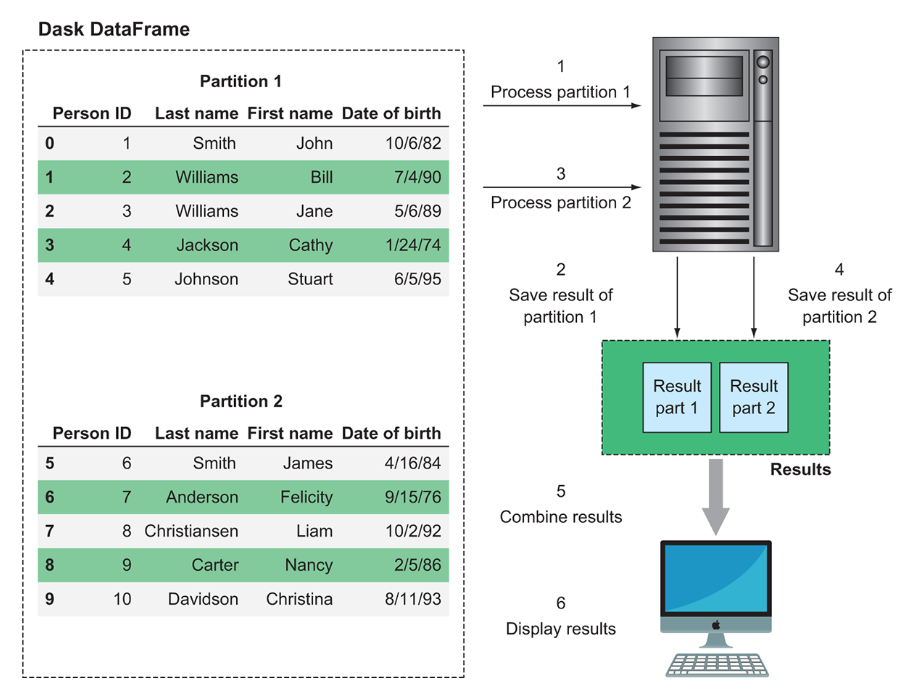
Harvard AC295 Lecture 4 Dask
Read_hdf (pattern, key[, start, stop,.]) read hdf files into a dask dataframe. Web read a parquet file into a dask dataframe. Raw_data_df = dd.read_parquet (path='dataset/parquet/2015.parquet/') i. Web i see two problems here. If it persists, you may want to lodge.

Writing Parquet Files with Dask using to_parquet
Web read a parquet file into a dask dataframe. Web 3 answers sorted by: Web this is interesting because when a list of parquet directories is passed to fastparquet, internally fastparquet. Web read a parquet file into a dask dataframe. Web parquet is a popular, columnar file format designed for efficient data storage and retrieval.
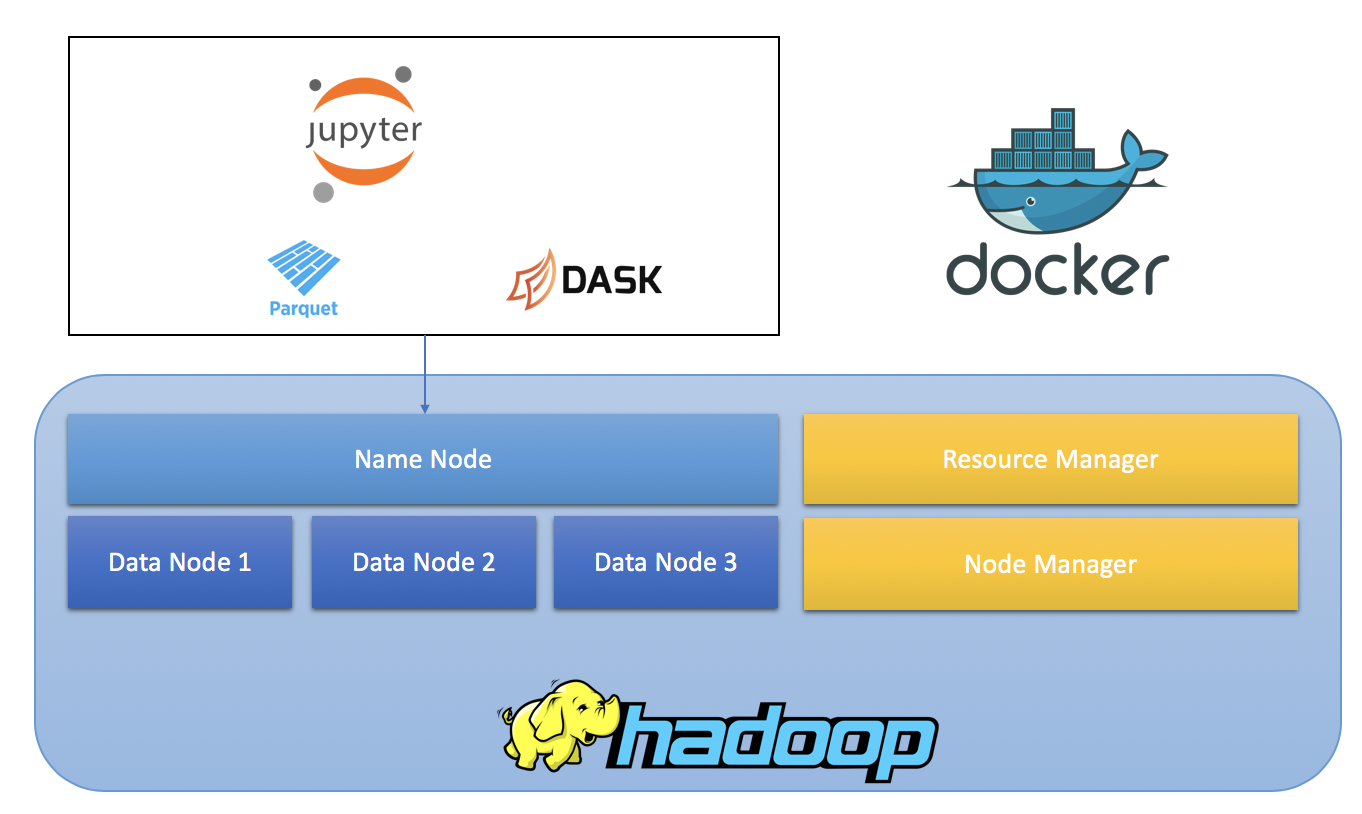
"FosforiVerdi" Working with HDFS, Parquet and Dask
Web 1 i would like to read multiple parquet files with different schemes to pandas dataframe with dask, and be able. In layman language a parquet is a open source file format that is designed. Raw_data_df = dd.read_parquet (path='dataset/parquet/2015.parquet/') i. Web when compared to formats like csv, parquet brings the following advantages: Web store dask.dataframe to parquet files parameters dfdask.dataframe.dataframe.

Nikita Dolgov's technical blog Reading Parquet file
Web parquet is a popular, columnar file format designed for efficient data storage and retrieval. Web below you can see an output of the script that shows memory usage. If it persists, you may want to lodge. Web 1 answer sorted by: Web when compared to formats like csv, parquet brings the following advantages:
PySpark read parquet Learn the use of READ PARQUET in PySpark
Web store dask.dataframe to parquet files parameters dfdask.dataframe.dataframe pathstring or pathlib.path destination. Web dask is a great technology for converting csv files to the parquet format. Web trying to read back: Web i see two problems here. This reads a directory of parquet data into a dask.dataframe, one file per partition.
read_parquet fails for nonstring column names · Issue 5000 · dask
Web when compared to formats like csv, parquet brings the following advantages: Web read a parquet file into a dask dataframe. Web how to read parquet data with dask? Pandas is good for converting a single csv. If it persists, you may want to lodge.

Read_parquet is slower than expected with S3 · Issue 9619 · dask/dask
Web parquet is a popular, columnar file format designed for efficient data storage and retrieval. Import dask.dataframe as dd in [2]: Web when compared to formats like csv, parquet brings the following advantages: Web create_metadata_filepyarrowcompute_kwargsconstruct a global _metadata file from a list of parquet files. Web i see two problems here.
Read_Parquet too slow between versions 1.* and 2.* · Issue 6376 · dask
Web parquet is a popular, columnar file format designed for efficient data storage and retrieval. Web read a parquet file into a dask dataframe. Read_hdf (pattern, key[, start, stop,.]) read hdf files into a dask dataframe. First, dask is not splitting your input file, thus it reads all the data in a single partition,. Web below you can see an.

Dask Read Parquet Files into DataFrames with read_parquet
Raw_data_df = dd.read_parquet (path='dataset/parquet/2015.parquet/') i. Web dask is a great technology for converting csv files to the parquet format. In layman language a parquet is a open source file format that is designed. Web read a parquet file into a dask dataframe. Web this is interesting because when a list of parquet directories is passed to fastparquet, internally fastparquet.
to_parquet creating files not globable by read_parquet · Issue 6099
In layman language a parquet is a open source file format that is designed. Web read a parquet file into a dask dataframe. 2 the text of the error suggests that the service was temporarily down. Web create_metadata_filepyarrowcompute_kwargsconstruct a global _metadata file from a list of parquet files. Web trying to read back:
If It Persists, You May Want To Lodge.
Web store dask.dataframe to parquet files parameters dfdask.dataframe.dataframe pathstring or pathlib.path destination. Web 1 answer sorted by: First, dask is not splitting your input file, thus it reads all the data in a single partition,. Web dask is a great technology for converting csv files to the parquet format.
Web This Is Interesting Because When A List Of Parquet Directories Is Passed To Fastparquet, Internally Fastparquet.
Web below you can see an output of the script that shows memory usage. Read_hdf (pattern, key[, start, stop,.]) read hdf files into a dask dataframe. Web create_metadata_filepyarrowcompute_kwargsconstruct a global _metadata file from a list of parquet files. Web how to read parquet data with dask?
4 This Does Work In Fastparquet On Master, If Using Either Absolute Paths Or Explicit Relative Paths:.
This reads a directory of parquet data into a dask.dataframe, one file per partition. Import dask.dataframe as dd in [2]: Web read a parquet file into a dask dataframe. Web read a parquet file into a dask dataframe.
Web When Compared To Formats Like Csv, Parquet Brings The Following Advantages:
Web 3 answers sorted by: In layman language a parquet is a open source file format that is designed. Web i attempted to do that using dask.delayed (which would allow me to decide which file goes into which. Raw_data_df = dd.read_parquet (path='dataset/parquet/2015.parquet/') i.